grepを使う
著者:梅谷 武
作成:2014-05-31
更新:2014-06-01
更新:2014-06-01
grepとはUNIXにおけるコマンドで、テキストファイルから指定したパターンの文字列を含む行を検索して出力するものです。
テキストファイルに含まれる文字列のパターンを表現する方法として、grepは正規表現(regular expression)を採用しています。
grepを使って正規表現で文字列を検索するというのは、元々はプログラミング技術として開発されたものですが、電子テキストが普及した現在においては、電子テキストを扱うすべての人々にとって、生産性向上のためにこれを習得することが必須になっています。
現在では多くのテキストエディタにgrepが内蔵されており、エディタの機能としてこれを使うことができるようになっています。
ここではftexのラテン語翻訳支援機能で作業するときに、頻繁に使うことが必要となる検索パターンを秀丸エディタで検索する例について説明しましょう。
正規表現は文字列のあるパターンを表わす文字列です。正規表現においてはほとんどの文字は、その文字そのものを表わしますが、例外的にその文字以外の意味をもつ文字があり、これをメタ文字(meta character)と呼びます。
ここではよく使う2つのメタ文字の意味を示しておきます。
| ^ | 行頭を表す |
| $ | 行末を表す |
ラテン語は屈折語であり語形変化するため、辞書を検索するときに先頭の数文字からなる語基を指定し、同じ語基をもつ単語をすべて列挙してみるという操作が必要になります。
例えば"vit"という語基を含む行をすべての辞書ファイルから抽出してみましょう。
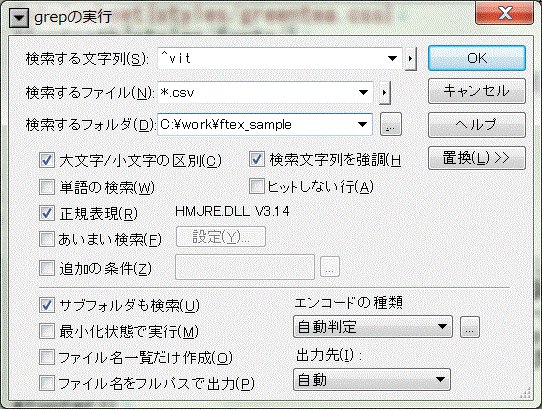
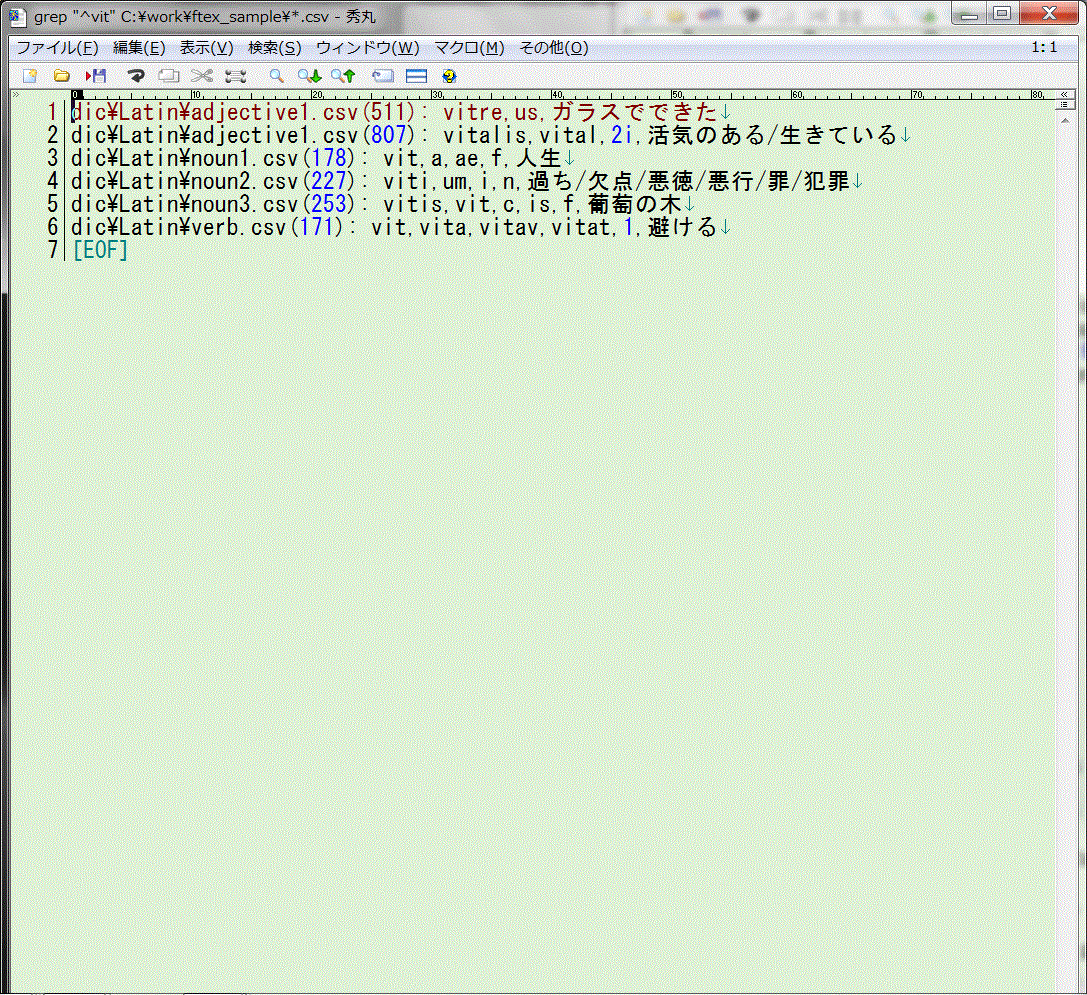
検索結果出力で目的の行にカーソルを合わせて[F10]を押すと、自動的に該当ファイルを開き、該当行にカーソルを移動します。
grepを使って辞書検索を行う場合、羅和、和羅の区別はありません。漢語の語基である漢字やひらがな、カタカナを使って検索できます。
例えば"円"を含む行をすべての辞書ファイルから抽出してみましょう。
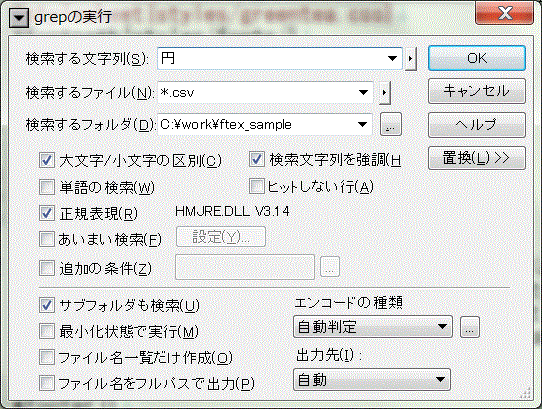
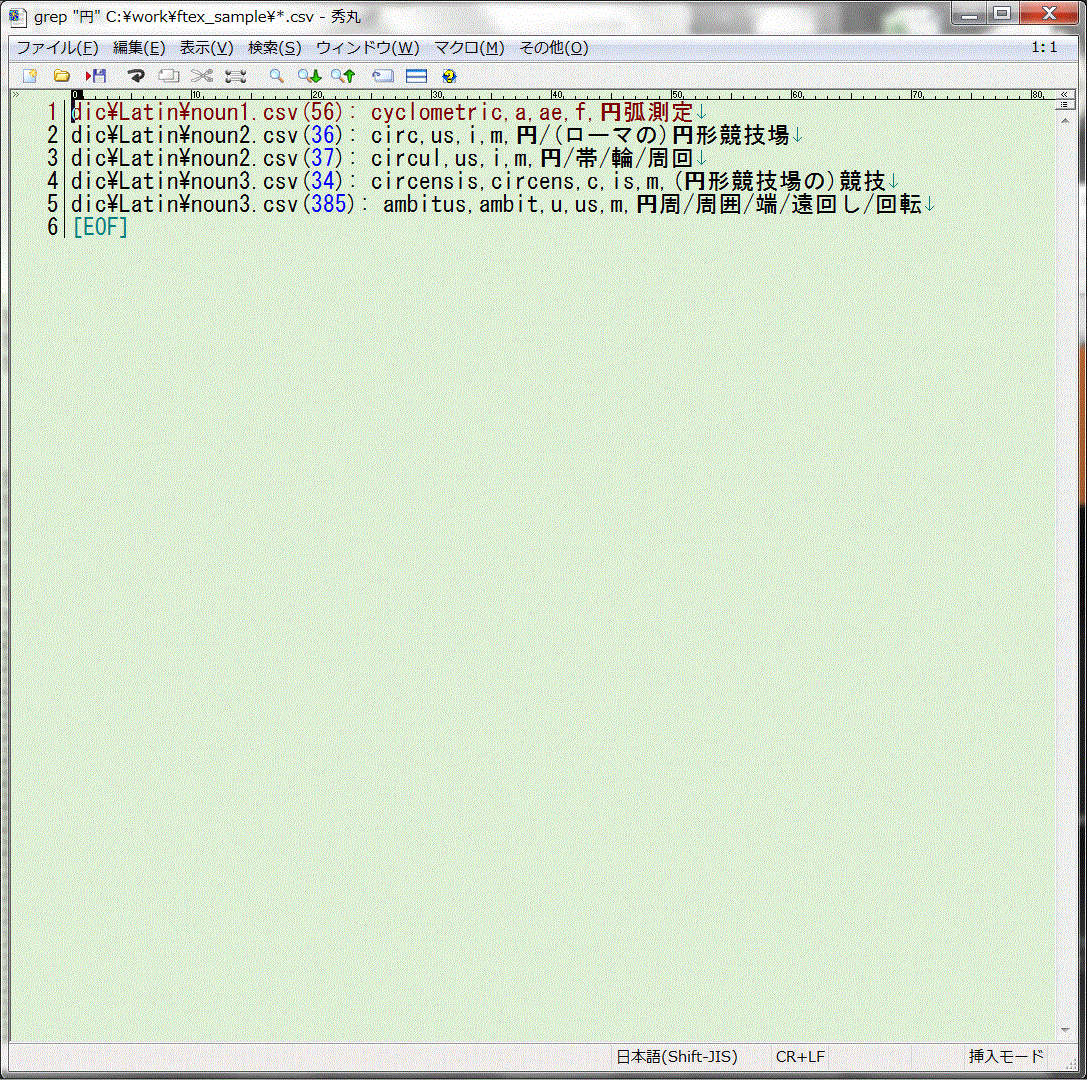
この検索結果により、"circ"が"円"に対応する語基であることがわかります。
